通过SPSS,我们可以对两个及以上数据进行相关性分析,即分析数据之间是否存在正相关或者负相关,相关的强度怎么样等等。比如,分析某个商品的价格与销量的关系等等。对两个独立样本进......
2023-12-22 208 SPSS对两个独立样本进行非参数检验
相关性分析是对变量或个案之间相关度的测量,在IBM SPSS Statistics中可以选择三种方法来进行相关性分析:双变量、偏相关和距离。
分析方法是操作手段,结果是得到分析后的数据列表,那么使用SPSS进行相关性分析后该如何查看并解读结果呢?下面整理了几种常见相关分析结果的解读,大家可以参考一下。
一、双变量分析
1.数据
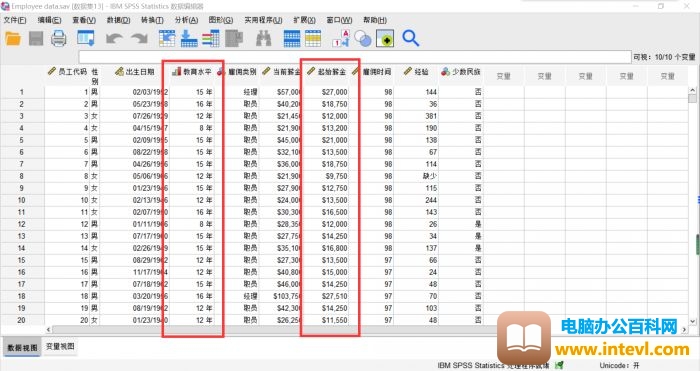
图1:数据列表
数据样本如上图所示,是某家公司录取员工的基本情况,我们要探究的是教育水平和起始薪金之间的相关性。
2.分析设置
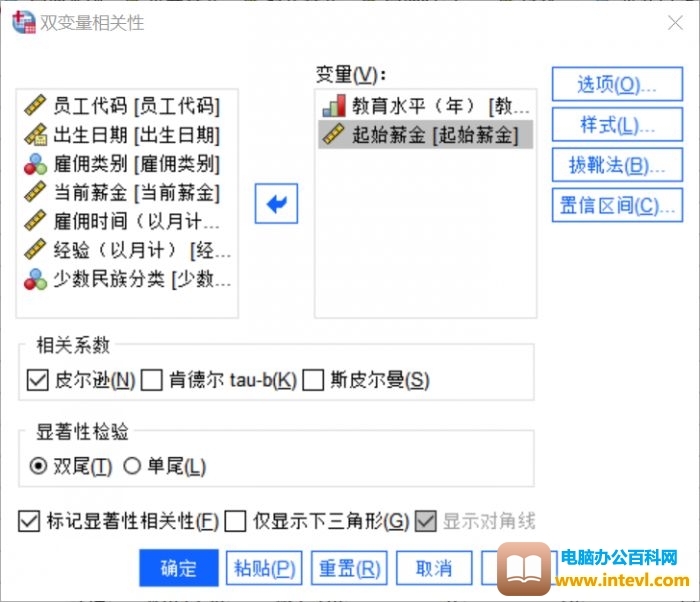
图2:双变量分析设置
对两个变量进行如上图设置,选择皮尔逊相关和双尾检验。
3.结果分析

图3:分析结果
结果中一般会有两个表(只运用一种分析方法),第一个表是频率统计和基本的计算结果,显示数据的平均值、标准差和个案数。
第二个表是表征数据相关性的,我们需要重点关注的一个参数是皮尔逊相关系数,也就是常说的p值,若这个值的绝对值大于0.05,就表示变量间存在显著相关性。
表中有两个数据被用星号标注,这就是大于0.05的p值,表明教育水平和起始薪金存在显著的正相关性。
二、偏相关分析
1.分析设置
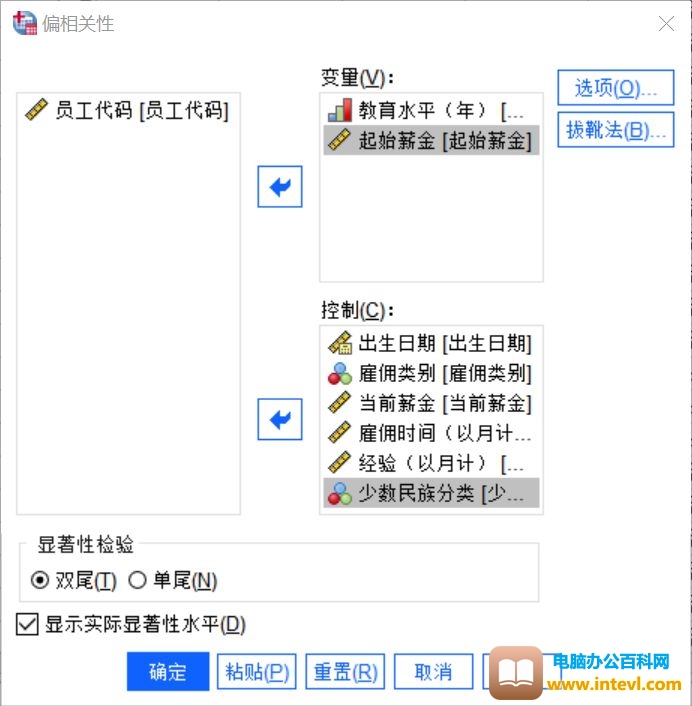
图4:分析设置
偏相关分析是用来剔除有关变量的干扰、用以分析其他变量之间相关性的方法。
同样使用上述样本,如果我们要更为精确地探讨起始薪金和教育水平的相关性,可以将其余变量都视作干扰变量全部剔除,分析设置如上图。
2.结果分析
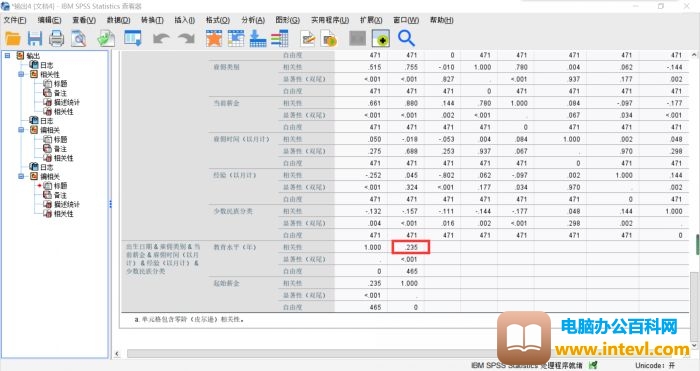
图5:偏相关结果
由于控制变量较多,这个表格也较为复杂,但可以直观看出每两个变量之间的相关性方向和强弱。
在表格最后,是控制变量后对教育水平和起始薪金的相关性分析,可以发现,其他变量被控制后,皮尔逊系数明显下降,由双变量分析中的0.633降为0.235,它们之间仍然具有正相关性,但相关程度大大降低。
由此可见,对于变量数目较多且关系复杂的数据,分析两个变量或特定变量之间的相关性时,使用偏相关分析结果会更为可靠一点。
三、距离分析
1.个案非相似性距离分析
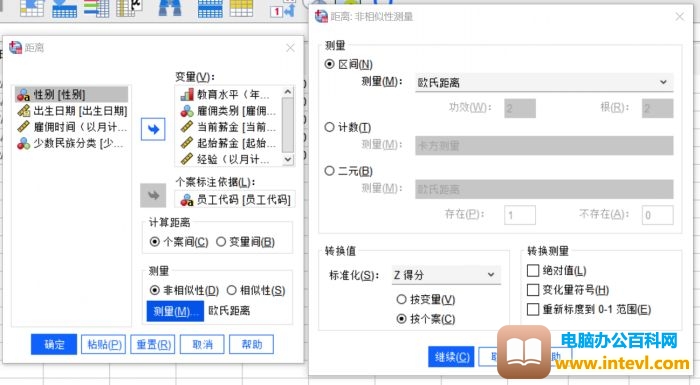
图6:距离分析设置
选择本数据样本的前五组数据作为分析对象,通过对教育水平、雇佣类别、起始薪金、现在薪金、经验几个变量的分析计算个案间的非相似性距离。

图7:结果分析
这种分析方法的结果是得到一个非相似性矩阵,表中的参数值越小,相似性越大,表中显示,个案2和个案5之间的距离最小,所以他们的相关性最强。
2.变量相关性距离分析
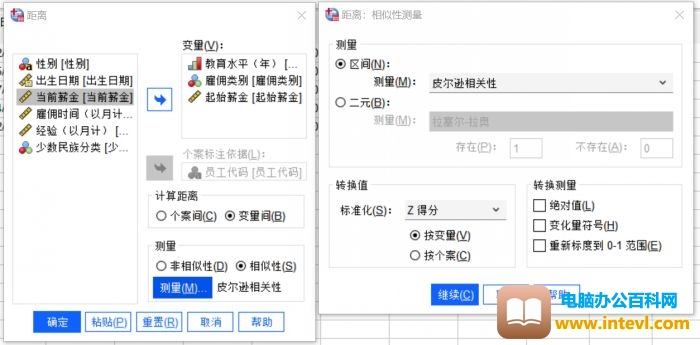
图8:分析设置
将分析对象变为个案,非相似性改为相似性,进行如上设置。
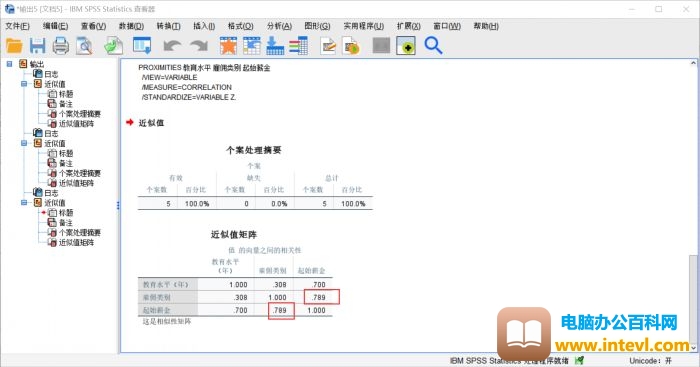
图9:结果分析
和非相似性矩阵类似,我们会得到一个相似性矩阵,其中的参数表示变量之间的相似性距离,参数越大,相关性越强。
从表中显示的参数来看,在被分析的三个变量中,起始薪金和雇佣类别的距离最大,相关性最强。
四、小结
关于使用SPSS相关性分析后的结果,本次的分享就到这里啦,三种方法的应用范围和分析精度都有所不同,大家根据自己需要选择即可,希望可以对大家有所帮助!
标签: SPSS相关性分析结果查看
相关文章

通过SPSS,我们可以对两个及以上数据进行相关性分析,即分析数据之间是否存在正相关或者负相关,相关的强度怎么样等等。比如,分析某个商品的价格与销量的关系等等。对两个独立样本进......
2023-12-22 208 SPSS对两个独立样本进行非参数检验

SPSS可以用于分析两个及以上的数据的相关性。相关性,顾名思义,就是两个及以上数据之间的相关程度,分为正相关和负相关,相关的强度又可以分为非常显著、显著和非常不显著哦。加入两......
2023-12-22 204 SPSS相关性分析
随机抽样,简单来说,就是在一个总体的全部数据中,保证每一个对象都有非零的概率被抽中,而进行的随机抽取出样本的方法。这种抽样方法在统计学中,是一个非常常见的数据统计分析方......
2023-12-22 204 SPSS进行随机抽样
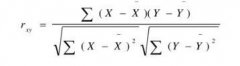
这篇文章将为大家介绍SPSS的积差相关分析的使用方法。 一、概述 相关关系指的是两个变量之间不精确、不稳定的变化关系,相关分析就是通过定量的指标来描述两个变量之间的相关关系,积......
2023-11-17 203 SPSS积差相关分析
小伙伴们在日常办公时,是不是也和很多人一样,经常遇到这样的情况呢,录入数据后,发现有一些小问题需要修改,或者是新增加了一些数据,需要加入到已有的数据文件中。在Excel表格中,......
2023-12-22 229 SPSS编辑数据